Monitorovanie sieťovej prevádzky existujúcich PDF zobrazovačov
V tomto dokumente sa pozrieme na existujúce digitálne knižnice, ktoré disponujú zobrazovačom PDF súborov.
Pozrieme sa na existujúce PDF zobrazovače a sústredíme sa na monitorovanie sieťovej prevádzky. Zaujímať nás budú jednotlivé "Requests" a "Response", z ktorý sa budeme snažiť zistiť, akým spôsobom je z PDF zobrazovača PDF súbor načítaný/zobrazený. Pomôžu nám v tom súbory typu .har (HTTP Archive). Následne použijeme online nástroj, ktorý nám .har súbory zobrazí v čitateľnej a štruktúrovanej podobne.
Venovať sa budeme existujúcim riešeniam:
Sieťová prevádzka a export .har súbora
Prístup k nej je možný pomocou Inspect a následne otvorenie Network sekcie, v ktorej vidíme jednotlivé requesty a tiež aj možnosť vyexportovať všetky tieto údaje do .har súbora, čo aj využijeme pri analýze.
Ukážka sekcie Network s možnosťou export HAR súboru:
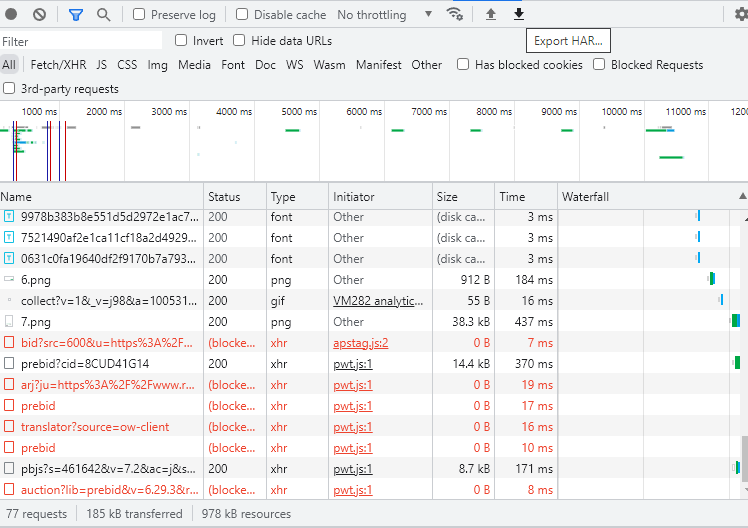
Zobrazovač HAR súborov
Pre čitateľnejší výstup a formát použijeme online webstránku, kde môžeme vložiť .har súbor. Na spodnom obrázku je príklad, ako vyzerá kompletný výstup a tiež poskytuje detailejšie informácie k jednotlivým requestom prípadne aj response. Pri analyzovaní existujúcih zobrazovačov sa budeme venovať iba špecifickým údajom, ktoré nám napovedia, akým spôsobom a kedy je PDF súbor requestovaní a zobrazovaný.
Ukážka výstupu z pomocného online nástroja pre HAR súbory:
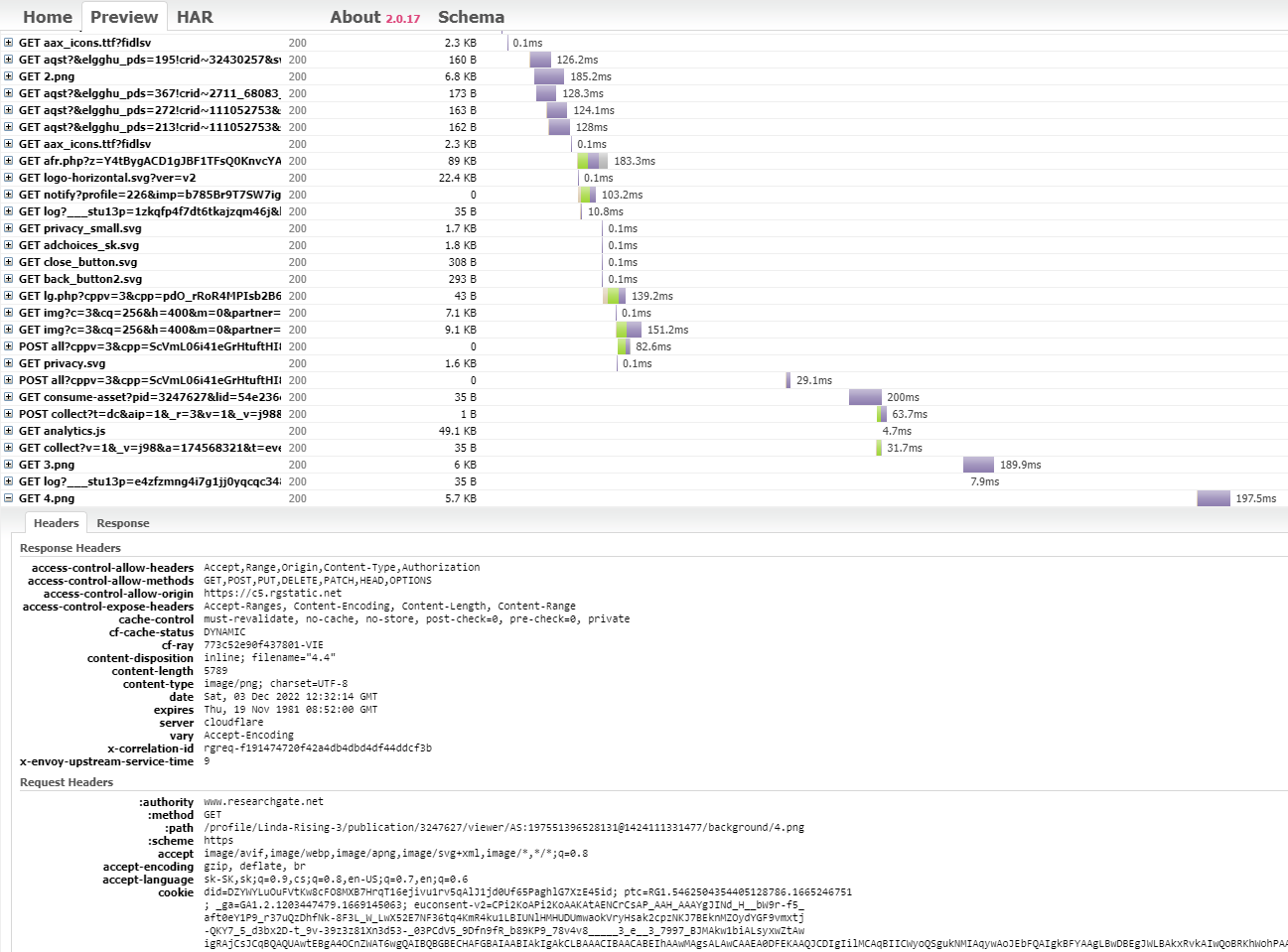
ResearchGate
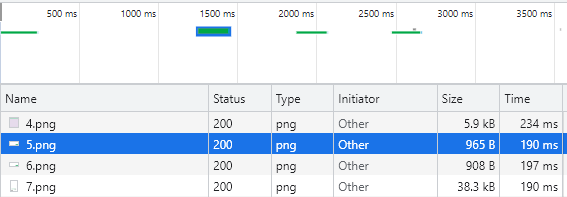
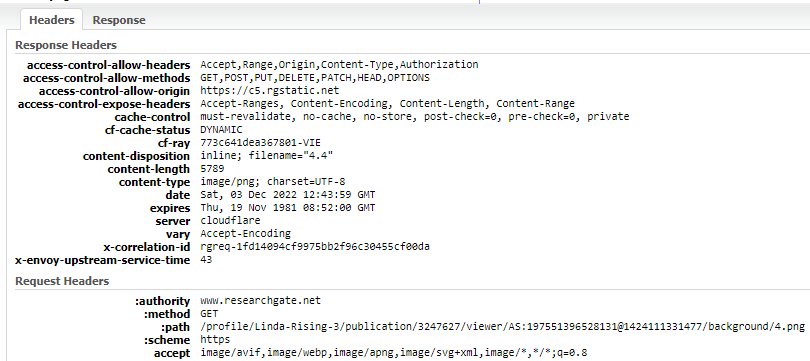
Ponúka možnosť zobraziť PDF dokument a následne pomocou scrollovania sa posúvať po stranách. Po načítaní stránky sme spustili zachytávanie premávky a teda Requestov. Postupne sme scrollovali smerom nadol, kde sme mohli vidieť a čítať samotný dokument. V Network vidíme .png súbory s jednotlivým číslovaním, ktoré prišlúchaju danej strane počas scrollovania. Postupne sme teda žiadali strany dokumentu, čo je aj vidieť na časovej osi:
Exportovaný .har súbor sme importovali do vyššie spomenutého zobrazovača, ktorého výstup bol nasledovný:
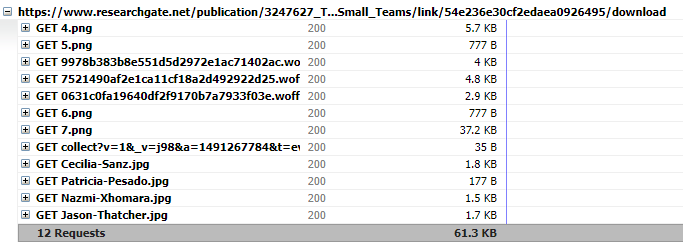
Postupne sme requestovali strany dokumentu, ktoré nám aj v reponse prišli, čo vo výsledku bola načítaná strana v PDF zobrazovači. Spodný obrázok ešte bližšie zobrazuje detaily napr. GET 4.png. Záverom je, že sme postupne po stranách získavali strany ako obrázok s koncovkou .png.
ACM Digital Library
Taktiež poskytuje PDF zobrazovač, ktorý sa otvorí sa samostatnom okne. Dokument načítava úplne iným spôsobom ako ResearchGate. Náš testovací dokument bol ihneď requestovaný a načítaný kompletne. Zaujimavosťou však je, že dokument bol posielaný nie ako jeden celok ale po častiach (HTTP Code 206 - Partial Content).
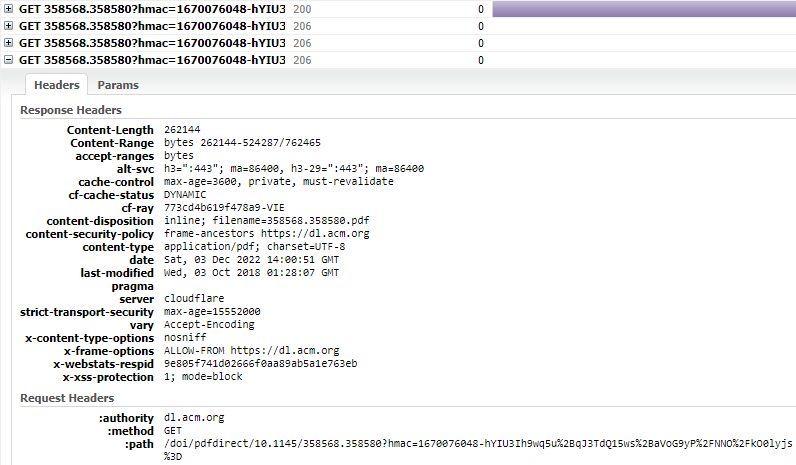
Z detailov napríklad posledného requestu vidíme, content-type application/pdf a v tomto prípade sme requestovali dokument typu PDF.
Univerzitná knižnica v Bratislave
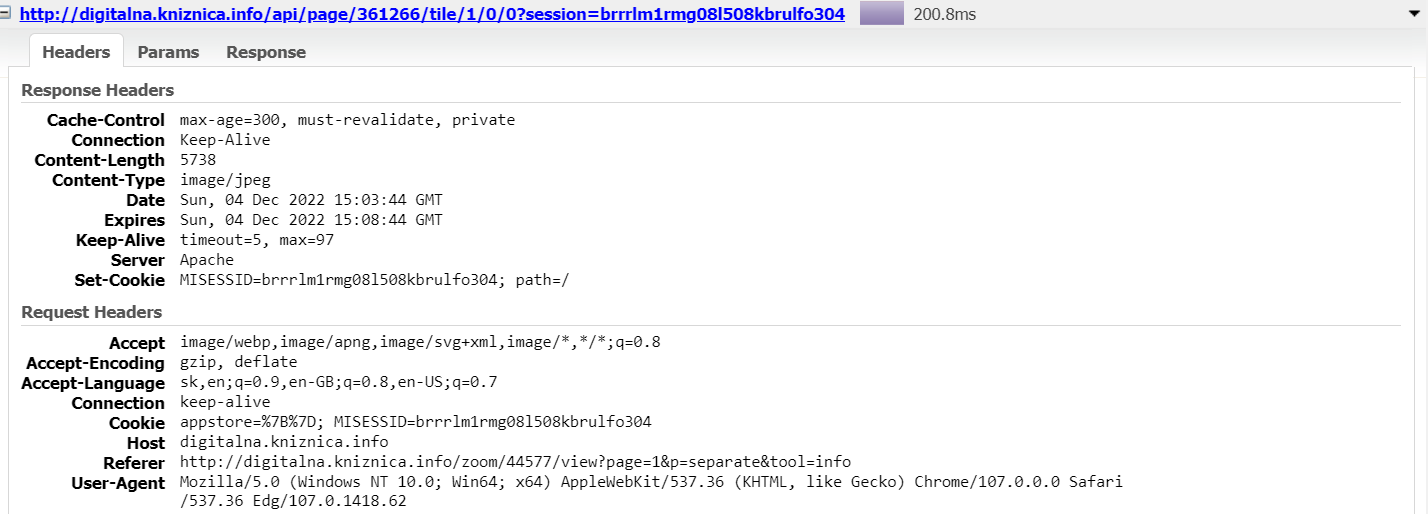
Viewer na stránke UKB zobrazuje dokument po stranách. Po otvorení dokumentu sa prijme JSON popisujúci atribúty dokumentu a atribúty jednotlivých strán(napr. id strany, rozmery, odkaz na tilemap). Samotná strana sa skladá z viacerých čiastkových obrázkov podľa štruktúry tile/{level}/{row}/{column}.
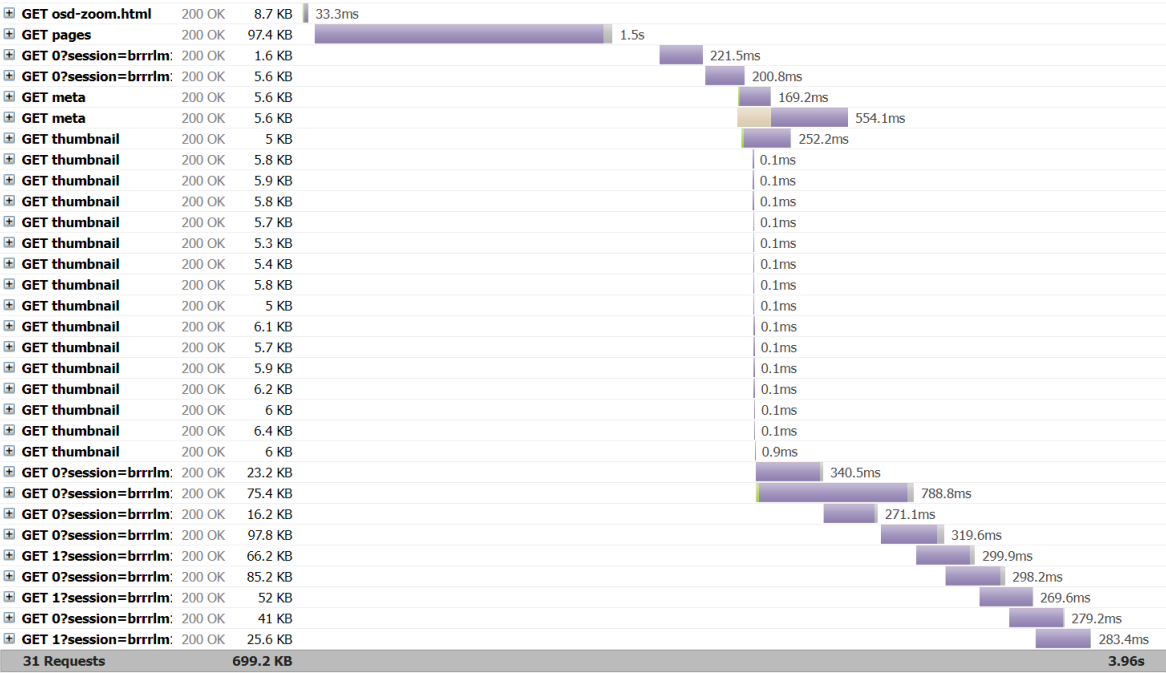
Thumbnail predstavuje miniatúru strany zobrazenú v náhľade strán pri navigácií.
Štruktúra GET metód:
- strana: GET
http://digitalna.kniznica.info/api/page/{pageID}/tile/{level}/{row}/{column}?session={session} - thumbnail: GET
http://digitalna.kniznica.info/api/page/{pageID}/thumbnail
V HTTP hlavičkách je definovaný Connection ako Keep-Alive a Content-Type ako image/jpeg.
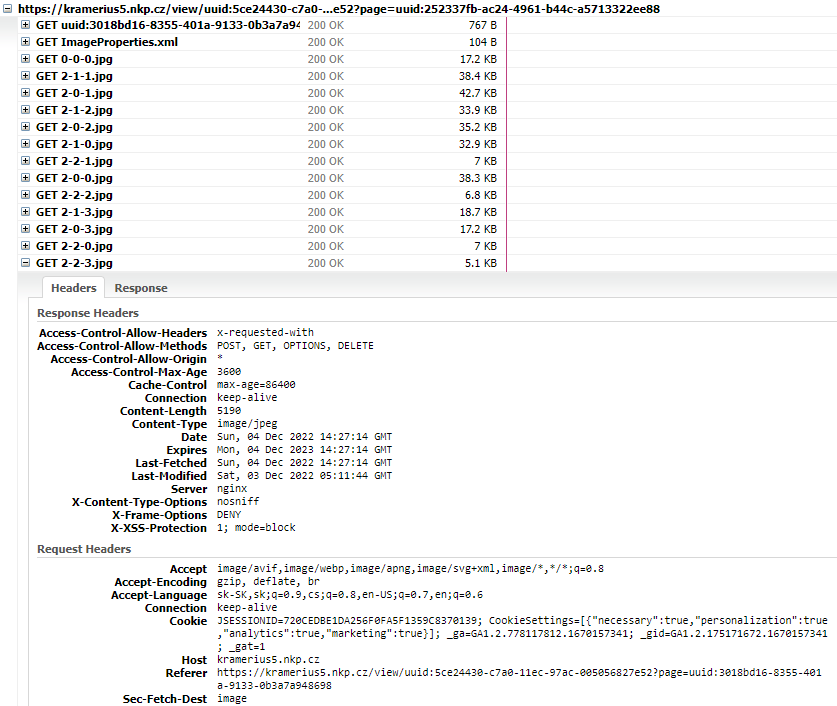
Národní knihovna České republiky
Vo viewri kramerius sme pri network analýze zistili, že vždy prichádzajú jpeg obrázky danej strany PDF, ktorá je otvorená. Z tejto skutočnosti usudzujeme, že Kramerius každú stranu rozkladá na viacero častí, ktoré jednotlivo posiela. Taktiež sme rovnaké správanie mohli zaznamenať pri približovaní a oddialení PDF. Prišli nám rôzne časti jpeg obrázkov, ktoré pravdepodobne predstavovali časť strany, ktorá je aktuálne renderovaná, pri posúvaní sa na danej priblíženej strane sme zaznamenali taktiež viacero jpeg obrázkov. Počet obrázkov, ktoré boli posielané pri posúvaní sa na zoomnutom dokumente sa zvýšil vždy, keď sme boli zoomnutí viac. To môže znamenať, že kramerius rozďeluje obrázok na viacero častí, z ktorých následne vyskladáva finálnu stranu, ktorá nám je zobrazená. Názvy týchto častí strany sú typu 4_0_1,4_0_3,... čím kramerius vie zistiť, v akom poradí má dokument poskladať.
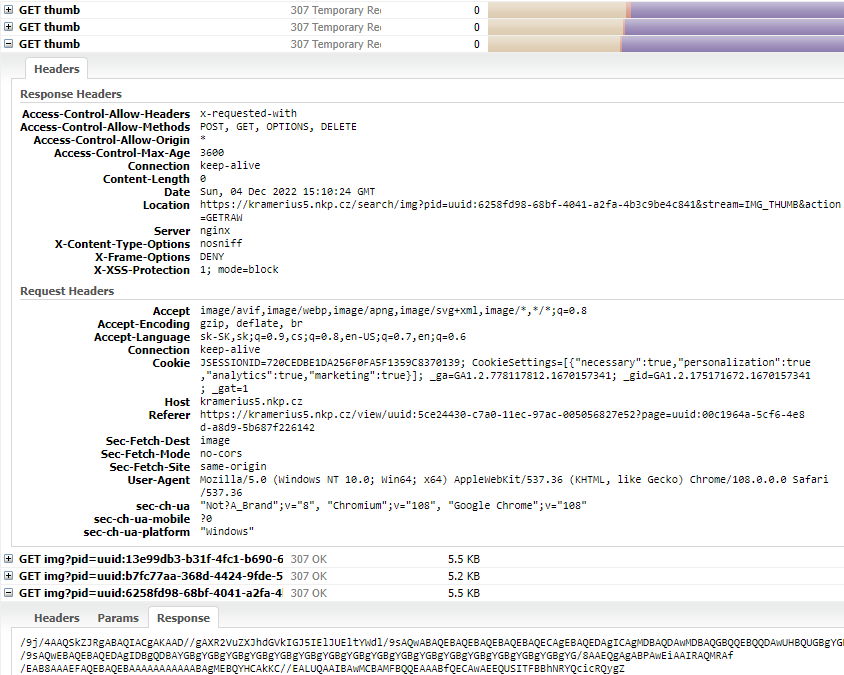
Pri scrollovaní ďalších(neotvorených) strán ďaného dokumentu sme obdržali 3 thumbnail jpeg obrázky, ktoré predstavujú nové zobrazené strany v menu. Tieto strany už neboli rozdelené na viacero častí. Pri vyhľadávaní v dokumente sme si taktiež všimli, že sa nám podobne ako pri scrollovaní v menu poslali všetky thumbnaily.
Z analýzy štyroch zobrazovačov vidíme, že každý z nich používa iný spôsob a nedá sa tvrdiť, že by existoval alebo bol nastavený jednotný spôsob zobrazovania PDF dokumentov.
Autori: Jakub Sorád, Matej Lánik, Róbert Szabó